1.找出問題
2.思考是否真的需要使用機器學習?
3.資料收集
4.資料前處理
5.特徵工程
6.模型訓練
7.模型評估
8.微調模型&參數
9.預測&部署模型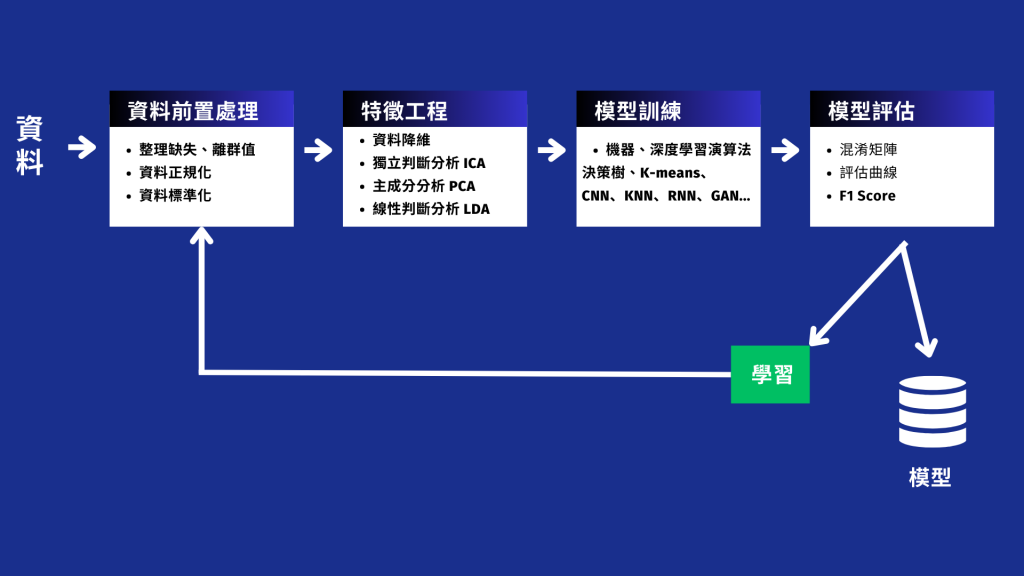
import pandas as pd
# 範例DataFrame
data = {'A': [1, 2, None, 4, 5],
'B': [None, 2, 3, 4, 5]}
df = pd.DataFrame(data)
print("Before")
print(df)
# 刪除包含缺失值的列
df.dropna(inplace=True)
# 填充缺失值,這裡用特定值(例如0)來填充缺失值
df.fillna(0, inplace=True)
print("After")
print(df)
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 範例DataFrame
data = {'Category': ['A', 'B', 'A', 'C', 'B']}
df = pd.DataFrame(data)
# 建立LabelEncoder物件
label_encoder = LabelEncoder()
# 使用LabelEncoder對類別特徵進行編碼
df['Category_Encoded'] = label_encoder.fit_transform(df['Category'])
print(df)
import pandas as pd
# 範例DataFrame
data = {'Category': ['A', 'B', 'A', 'C', 'B']}
df = pd.DataFrame(data)
# 使用get_dummies進行One-hot Encoding
df_encoded = pd.get_dummies(df, columns=['Category'], prefix=['Category'])
print(df_encoded)
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 範例DataFrame
data = {'A': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
print(df)
# 使用MinMaxScaler進行Max-Min正規化
minmax_scaler = MinMaxScaler()
df['A'] = minmax_scaler.fit_transform(df[['A']])
print("Max-Min",df)
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 範例DataFrame
data = {'A': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
print(df)
# 使用StandardScaler進行Z-Score正規化
zscore_scaler = StandardScaler()
df['A'] = zscore_scaler.fit_transform(df[['A']])
print("Max-Min",df)


 iThome鐵人賽
iThome鐵人賽